Jira Epics Are Dead Weight: Markdown and AI Agents Handle It Now
I have not estimated a ticket higher than one story point in months. Not because the work got easier, but because AI agents changed the unit of effort so fundamentally that the old scale stopped making sense. When a well-scoped task takes an agent five minutes, the distinction between a "3" and a "5" is fiction. And once every ticket is a 1, you start asking a question that would have been heresy two years ago: why are we maintaining Jira Epics and User Stories at all?
This post is about what I have been doing instead. Plans written in markdown, committed alongside code, with AI agents that read those plans and execute against them. It is not a theoretical framework. It is how this site was built, and it is how I think engineering-focused teams should be working right now.
The Migration Is Already Happening
I am not the first person to notice that Jira feels increasingly heavy for developer-led work. The signal is everywhere.
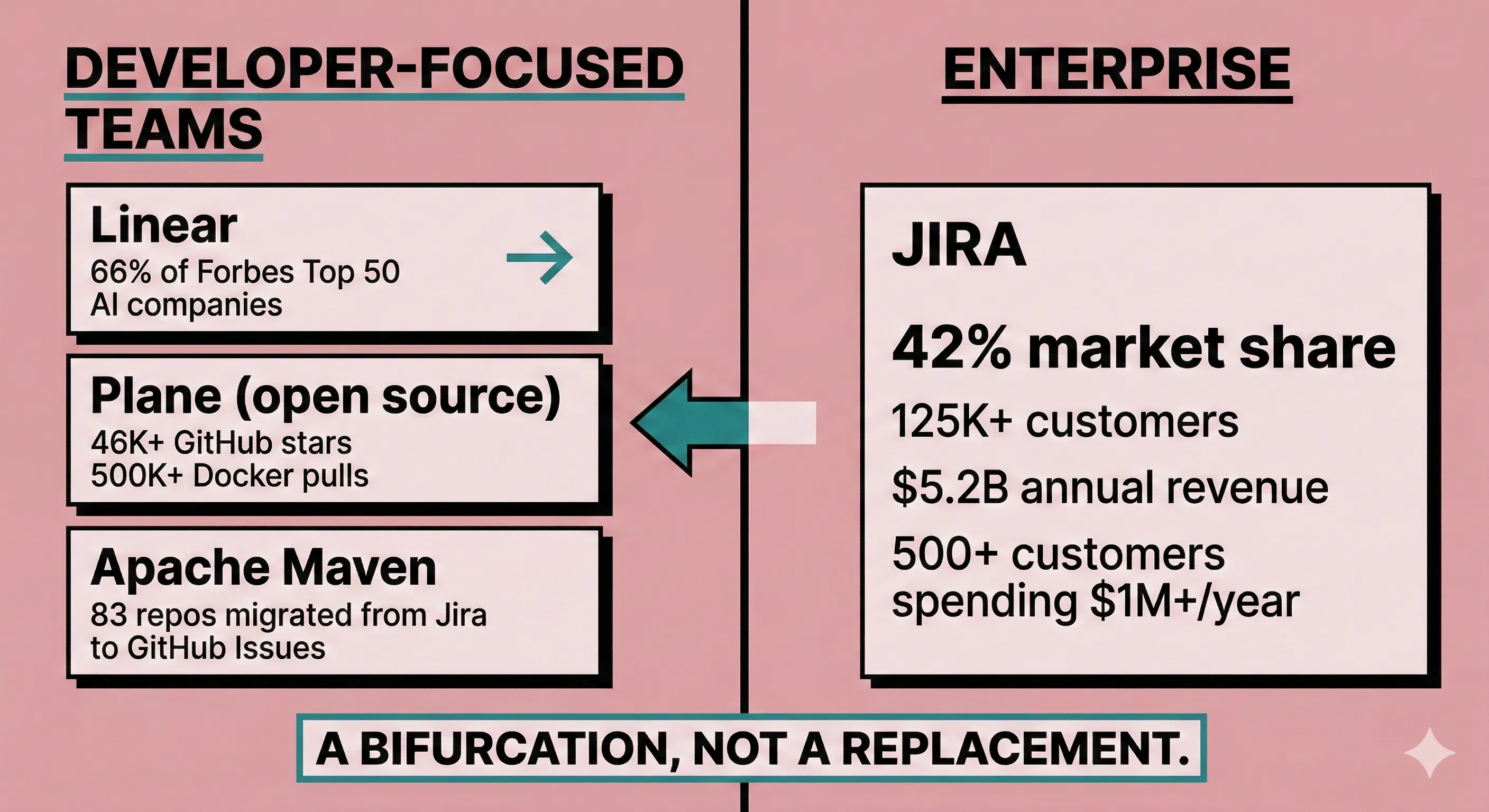
Apache Maven migrated 83 repositories from Jira to GitHub Issues across 2024-2025. Their stated motivation: "issues and source code are closer together." Infinispan, backed by Red Hat, made the same move in November 2024.
The numbers back them up. Linear is used by 66% of Forbes Top 50 AI companies. Plane, the open-source alternative, has pulled 46,000+ GitHub stars and 500,000+ Docker pulls. The pattern is consistent: developer-focused teams are choosing tools that stay closer to their existing workflow rather than forcing them into a separate system. To be clear, Linear and Plane are still structured tools with GUIs. Markdown-in-repos is a further step down that spectrum. But the direction of movement is what matters: toward code, away from heavyweight process.
But I want to be honest about the scale of what we are talking about. Jira still controls 42% of the project management market with 125,000+ customers and $5.2 billion in annual revenue growing nearly 20% year over year. Over 500 customers spend more than $1 million annually on Atlassian products. The companies leaving Jira are overwhelmingly developer-focused teams. The ones staying are enterprises with cross-functional needs. This is a bifurcation, not a replacement.
Why Markdown Plus AI Agents Work Now
I tried plain-text project management years ago. It did not work. You would write a plan in a README, forget to update it, and six weeks later it was a fossil. What changed is not the format. What changed is that AI agents can now read planning artifacts and act on them.
This is the core of the argument: the proximity of planning documents to code, combined with agents that operate on both, creates a feedback loop tighter than any external tool can match.
The tooling that makes it real
A new category of tools treats planning artifacts as code:
- Claude Code (launched January 2025) operates directly in your terminal, reads your repo's planning artifacts, executes multi-step tasks, and manages its own task lifecycle with dependency support. This site was built with it.
- Augment Code's Tasklist introduces typed tasks as first-class objects with state, timestamps, and parent relationships, enforcing long-horizon plans while keeping individual task context windows manageable.
- The AGENTS.md standard, now under the Linux Foundation's Agentic AI Foundation, is supported by OpenAI Codex, Google Jules, Cursor, and others. It provides a cross-tool convention for AI agent instructions in repositories.
- GitHub Copilot's coding agent (GA 2025) accepts an issue, runs in GitHub Actions, and submits a draft PR.
The context advantage
Here is the technical case that convinced me. Markdown planning files are inherently more context-friendly for AI agents than Jira data. They are plain text (no API translation needed), version-controlled (agents can see history), structured by convention (headings, checkboxes, links), and co-located with the code they describe.
An AI agent reading a CLAUDE.md, a ROADMAP.md, and the relevant source files has a tighter, more coherent context window than one querying Jira's REST API, parsing JSON responses, and trying to correlate tickets with code. This matters because of the "Lost in the Middle" effect: LLM performance degrades 30%+ when relevant information sits in the middle of the context window rather than at the beginning or end. Every API hop, every JSON parse, every field mapping is noise in the context window.
And Jira's own AI integration story is not encouraging. Atlassian's official MCP server cannot handle custom fields reliably and suffers from intermittent issues that limit its usefulness. Basic CRUD works, but not at the capacity that makes it a dependable part of your workflow. The fragmentation across five or more community-built Jira MCP servers illustrates how difficult it is to bridge legacy project management tools with AI agents. I have seen this firsthand: basic Jira operations work through MCPs, but the moment you touch custom fields, the integration falls apart. We are actually considering stripping our Jira instance back to defaults just to see if a cleaner configuration plays better with AI tooling. Why fight that battle when a codebase can hold the documentation for current work natively?
What this looks like in practice
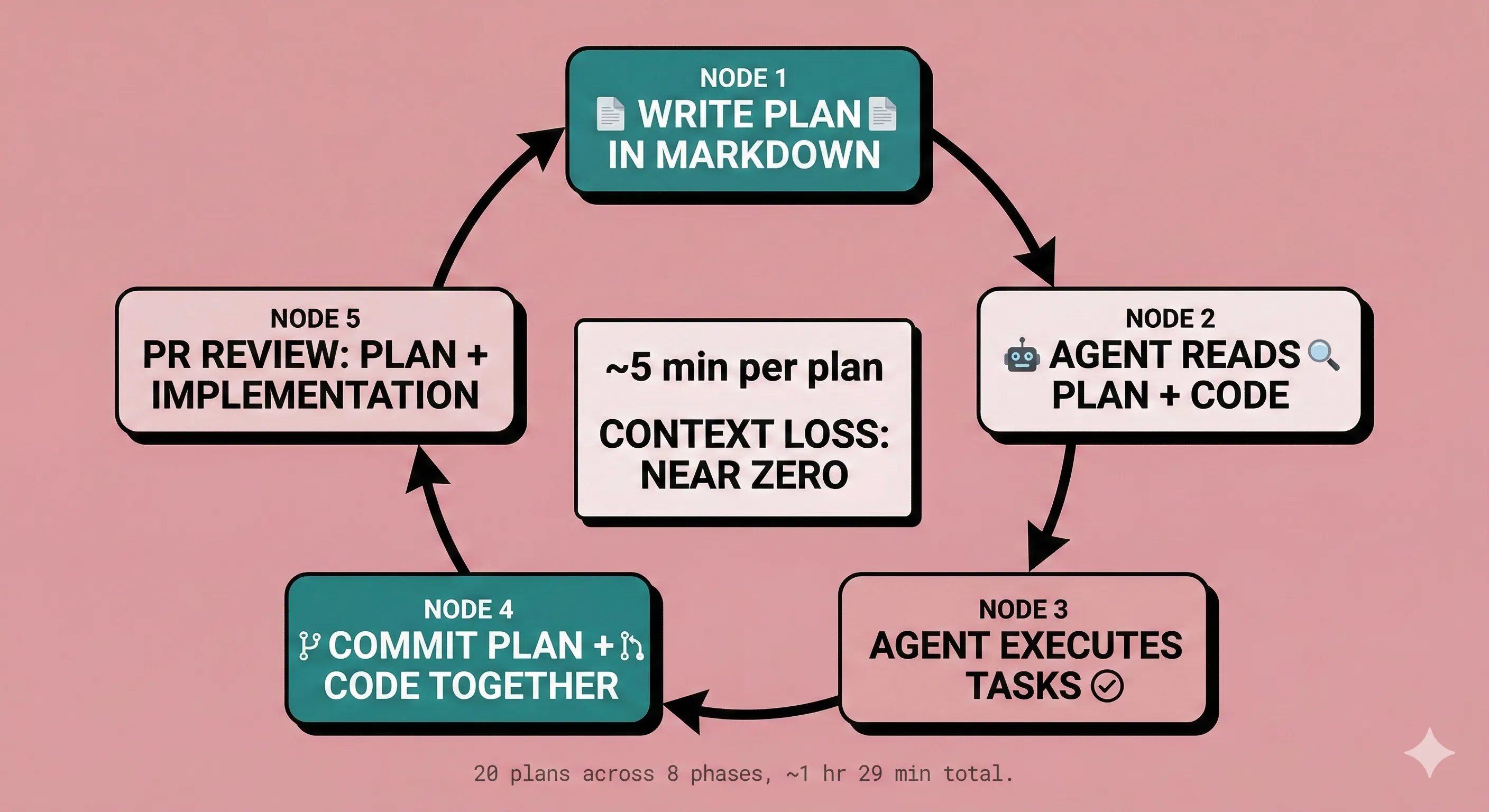
This site is the proof point. The .planning/ directory contains 20 completed plans across 8 phases, executed in roughly one working day (about 25 minutes per plan on average). Each plan is a markdown file. Each plan is version-controlled. Each plan was readable by the AI agent that executed it. This is a greenfield solo project, and those numbers should be read accordingly. The workflow scales differently when you add legacy code, shared state, and production constraints. But the structure (plan in repo, agent reads repo, code ships with plan) holds regardless of the throughput.
Here is what a typical planning artifact looks like:
# Phase 05: Blog Post View Counter
## Goal
Add view counting to blog posts using Upstash Redis with
IP-based deduplication.
## Tasks
- [ ] Create Redis client wrapper in src/lib/redis.ts
- [ ] Add GET/POST API route for single post views
- [ ] Add batch GET route for listing page counts
- [ ] Build ViewCounter client component with localStorage cache
- [ ] Build ListingViewCounts context provider
## Constraints
- Views are non-critical UI: all fetches fail silently
- IP hashes use SHA-256 with 24h TTL for deduplication
- No client-side flicker on repeat visits (localStorage read-through)An AI agent reads that file, understands the goal, sees the constraints, and executes the tasks in order. No Jira ticket needed. No Epic to nest it under. No story point to argue about in planning poker. The plan is the spec, the spec is in the repo, and the agent reads the repo.
From Estimation to Specification
Story points were always a proxy for uncertainty. "How hard is this?" was really "how much do we not know about this?" When AI agents can execute a well-decomposed task in minutes, the question shifts from "how hard" to "how clearly can I describe it?"
This reframes project management from estimation to specification. And specification is exactly what markdown excels at.
What estimation looks like now
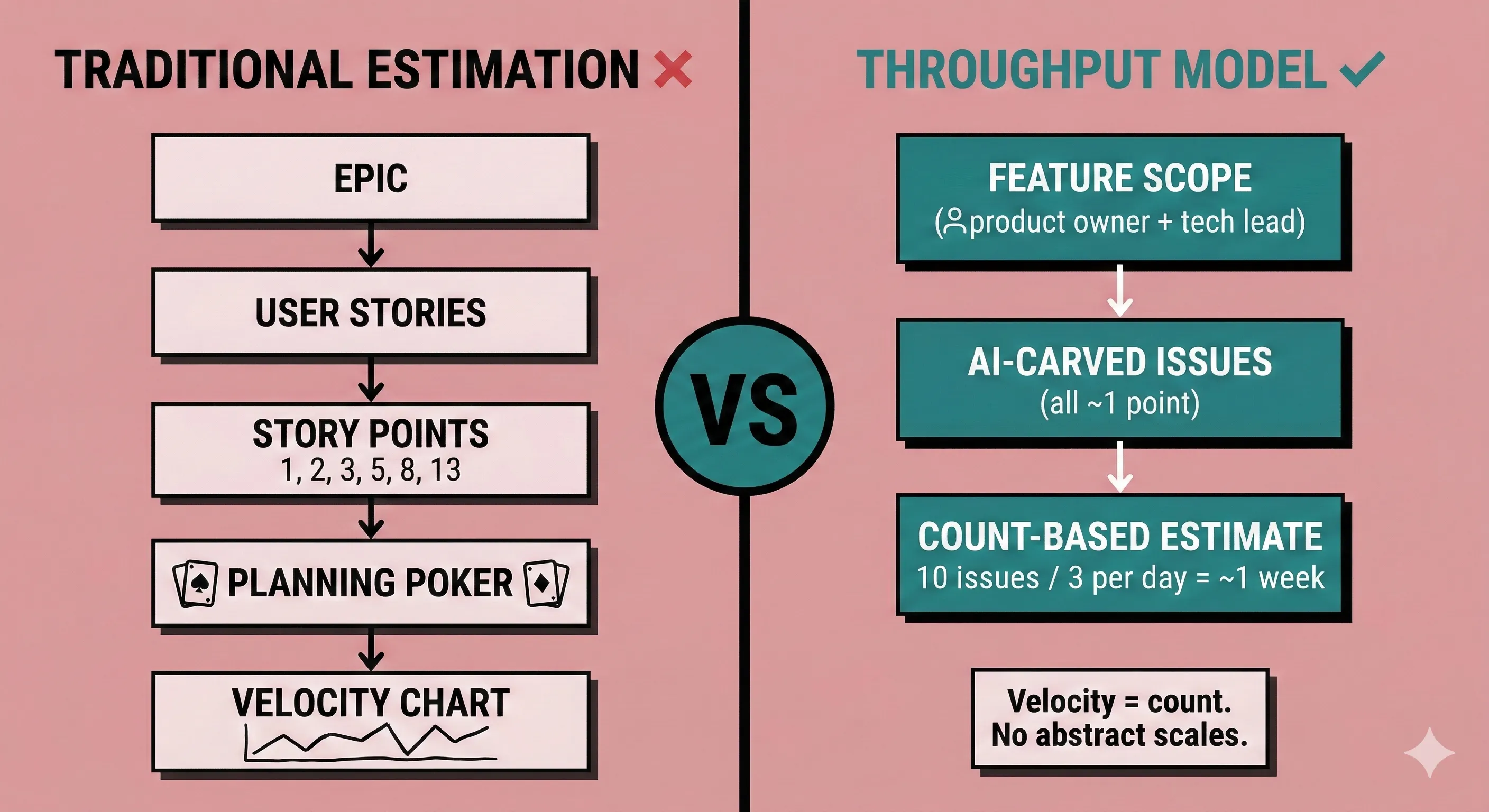
Here is what I think works better than the traditional Epic/Story/Point hierarchy:
Estimation happens at the feature level, between the product owner and tech lead. You describe the feature, scope the boundaries, and agree on the general size. Then AI pre-carves approximately similar-sized issues from that feature description. You count the issues to estimate practically. Ten issues at your team's throughput rate of three per day? That is a week of work. This works because you review the decomposition before committing to it. If an issue looks twice as heavy as the others, you split it further or flag it. The uniformity is curated, not assumed. No planning poker. No negotiation over whether something is a 3 or a 5.
This aligns with what Thomas Owens at Scrum.org has been recommending: move to throughput and cycle time over story points, which "removes questions about what to do when outside factors change the effort or complexity of work." The Development Bank of Canada achieved 51% faster delivery through better story slicing and data analysis rather than story point reliance.
Pierre Gilbert's critique lands harder in this context: "Comparing velocities encourages competition, local optimization and story points gamification instead of true collaboration." When every ticket is a 1, velocity is just a count. And a count is a better planning tool than an abstract scale that everyone interprets differently.
The real-time feedback loop
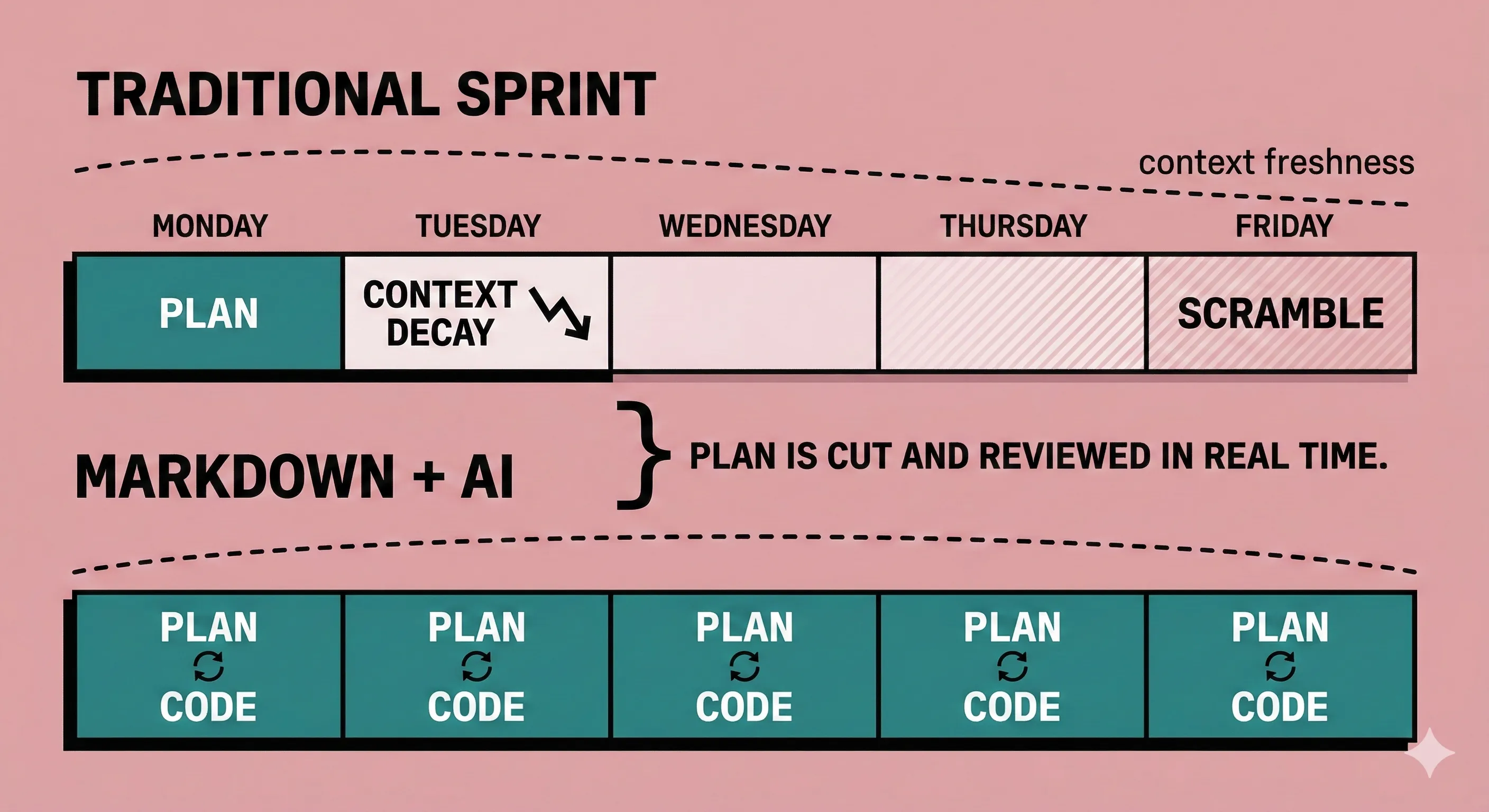
The other shift is temporal. Traditional sprint planning front-loads all the decision-making: you estimate, assign, and sequence work days before anyone touches code. By the time a developer starts a task, the original context has partially decayed.
With markdown-based planning, the plan is cut and reviewed in real time as the developer begins work. Code follows immediately while ideas are fresh. I have found this produces more predictable and repeatable outcomes than the traditional cycle of plan-on-Monday, forget-context-by-Wednesday, scramble-on-Friday.
The plan is a living document. It gets committed with the code it describes. When you review the PR, you review the plan and the implementation together. Context loss drops to near zero.
Where This Breaks Down
I would be dishonest if I pitched this as a universal solution. The research and my own experience converge on a clear set of boundaries.
Compliance and audit trails
This is where I expected the argument to fall apart, but the reality is more nuanced. SOC2's change management requirements (CC8) can largely be satisfied by git-based workflows: commit history provides tamper-resistant change records, PR reviews document segregation of duties, and branch protection rules enforce authorization chains. Frameworks like BMAD explicitly maintain a compliance ledger in git-versioned markdown artifacts that maps to SOC2 and HIPAA controls. In fintech, where I work, SOC2 is the primary compliance standard, and the documentation trail that a well-structured markdown workflow produces is arguably more auditable than a Jira board. That said, auditors expect dashboards, exportable reports, and access control matrices. You can build those from git history, but you are effectively rebuilding the reporting layer that tools like Jira already provide out of the box.
SOX and PCI-DSS are a different story. They require stricter controls, longer retention periods, and specialized reporting that git alone cannot provide. But most engineering teams are not operating under those frameworks directly. Their compliance obligations are SOC2, and git handles that better than many assume.
Non-technical stakeholders
Product managers, designers, QA leads, marketing, legal, and executives need project visibility. GitHub is an alien landscape for most business users. Jira's web UI, for all its slowness, is accessible to anyone with a browser. Markdown files in a repository require at minimum a GitHub account and comfort navigating a file tree. That is a real barrier.
That said, this is a barrier that AI could dissolve. Imagine an internal chatbot backed by a RAG pipeline over all of your organization's repositories. A product manager asks "what is the status of the payments refactor?" and gets a synthesized answer drawn from the actual planning documents, commit history, and open PRs across every relevant repo. No one needs to navigate a file tree. No one needs a GitHub account. The interface is a conversation, and the source of truth is still the codebase. This does not exist as a turnkey product today. Building and maintaining that pipeline is a nontrivial project in its own right (retrieval quality, access control, keeping embeddings current), so the stakeholder visibility gap is real and present. But the architecture is viable, and it is a matter of engineering effort, not a missing breakthrough.
Scale and monorepos
GitHub Issues works at roughly 10,000 issues but barely. Issues are flat, lack dependency management, and cannot compute critical paths. When I think about where markdown-based planning would struggle most in my own work, it is in large monorepos where multiple teams need unified views and portfolio-level reporting. Cross-repo aggregation does not exist in markdown. There is also the question of conflict resolution: multiple teams editing shared planning documents will inevitably produce merge conflicts, and unlike code conflicts where tooling and tests help you validate the resolution, conflicts in planning prose are harder to resolve with confidence.
The AI reliability gap
AI agents are not infallible. GitHub Copilot's coding agent achieves only a 40-60% success rate on well-scoped issues. Claude Code performs significantly better in my experience, but it still requires a developer who can review output critically.
The thesis that markdown plus agents replaces Jira depends on agents being reliable enough to execute plans autonomously. At 40-60% success rates, you still need significant human oversight. The tooling is improving fast, but the current state demands honesty: this workflow works best for teams that already have strong engineering discipline.

A surprising absence
Despite extensive searching, the research turned up zero documented cases of teams that tried markdown or git-based alternatives and returned to Jira. This could be survivorship bias (teams that came back do not write blog posts about it). Or it could mean that teams self-select correctly: those who leave Jira are the ones for whom it genuinely was not working. Either way, the absence is notable.
The Boundary, Not the Binary
I am not arguing that a 500-person regulated enterprise should put its project management in markdown files. And I am not arguing that you should cancel your Jira subscription tomorrow.
Here is what I am arguing: stop requiring Epics and User Stories in Jira for engineering teams that have adopted AI agents effectively. Those teams can manage task decomposition themselves. The plans live in the codebase. The agents read the plans and execute against them. The overhead of maintaining a parallel tracking system in Jira, translating between what the code says and what the ticket says, is pure waste.
Keep Jira for what it does well: cross-functional visibility, compliance tracking, executive reporting, and portfolio management. But let engineering teams that have the discipline and the tooling manage their own work in the medium they already live in.
The fragmentation is real. Claude wants CLAUDE.md, Cursor wants .cursorrules, Copilot wants .github/copilot-instructions.md. But AGENTS.md is converging the standard under the Linux Foundation with support from OpenAI, Google, Cursor, and others. Fragmentation is a sign of early-stage evolution, not a fundamental flaw. The tools will only get better. The agents will only get more reliable. And the gravity pulling planning artifacts toward the codebase will only get stronger.
The question is not whether this transition will happen. It is whether your team will lead it or be dragged into it when the tools mature enough that the holdouts can no longer justify the overhead.