Your Code Reviews Were Not Built for This
I have been watching developers get increasingly frustrated with the influx of large PRs, and the root cause is not always obvious. Teams are producing code faster than ever. The agents are humming. Features that used to take a week land in two days. But the review cycle has not kept pace, and the reviews themselves feel different. Reviewers are spending more time staring at code nobody on the team actually wrote, trying to assess reasoning that was never there. The old playbook for code review does not account for any of this, and pretending otherwise is costing us.
This post lays out what I think needs to change: the mental model behind code review responsibility, the role of nitpick culture, and where human attention should actually go when AI is writing most of the code.
Code Review Was Never Really About Catching Bugs
Before we talk about what needs to change, it helps to acknowledge what code review was actually doing for us. The answer might surprise you.
I used to believe the primary purpose of code review was catching defects before they hit production. Most engineering leaders I have talked to believed the same thing. But the data tells a different story. Bacchelli and Bird's study at Microsoft analyzed 570 review comments and found that defect-related comments made up only about 12.5% of all review feedback, and those were mostly "micro-level and superficial." The actual top outcomes were knowledge transfer, team awareness, and code readability improvements.
Google says the same thing explicitly. In Software Engineering at Google, they note that "checking for code correctness is not the primary benefit Google accrues from the process of code review." What Google values is comprehension, consistency, and collective ownership.
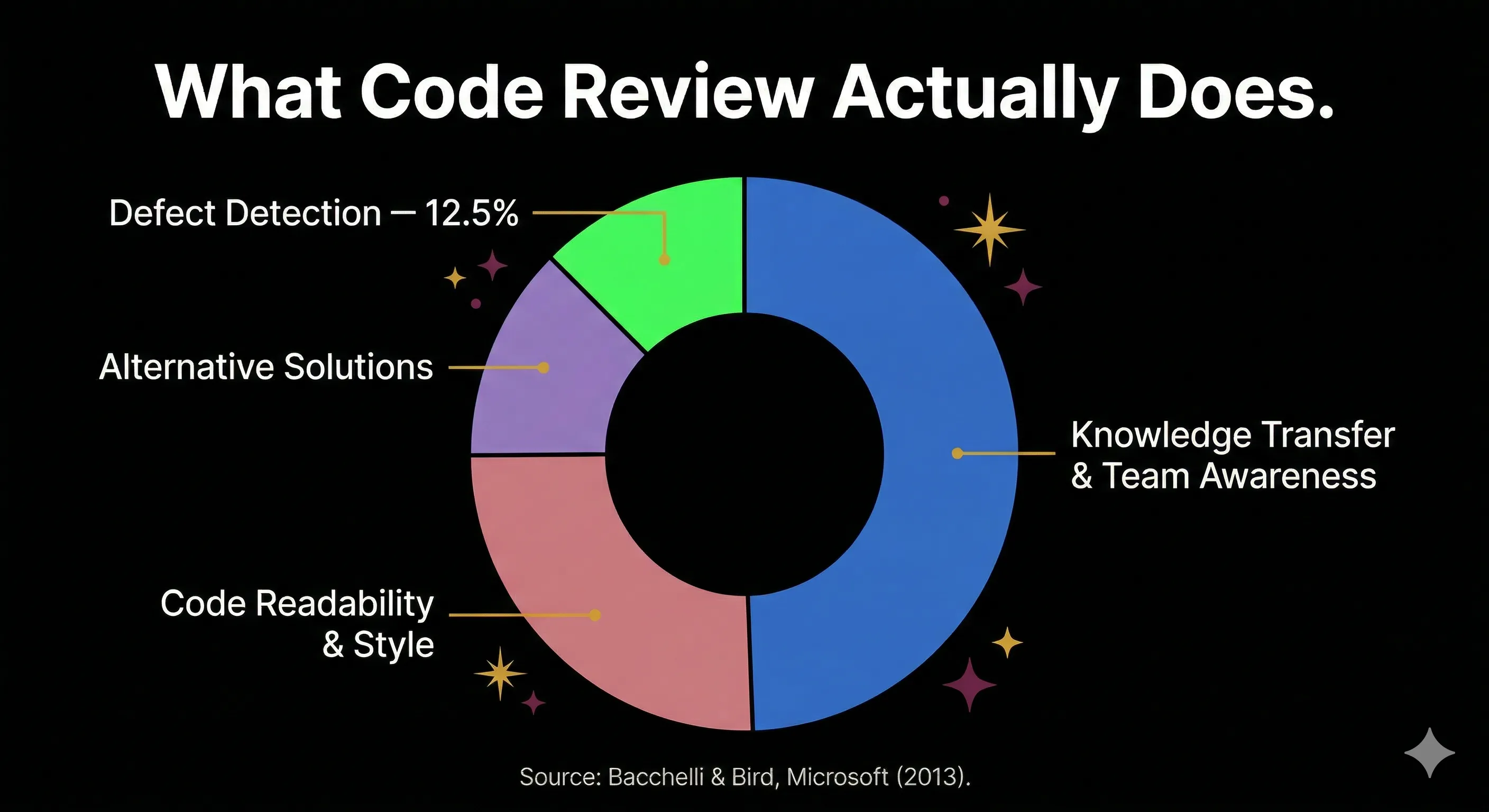
This reframes the entire AI conversation. If code review was never great at finding bugs, then the panic about AI code slipping past reviewers is misplaced. The real question is: what happens to knowledge transfer and team cohesion when most of the code is not written by a human on the team?
The Volume Problem You Cannot Solve With Willpower
Here is where the math stops working. My team's PR volume has roughly doubled since we started using AI coding agents seriously. That tracks with what Faros AI found across 10,000 developers and 1,255 teams: high AI adoption teams merge 98% more PRs, but review time increases 91%. PRs are also 154% larger on average.
The SmartBear/Cisco study established decades ago that beyond 400 lines of code per hour, defect detection collapses. At rates above 450 LOC/hour, defect density falls below average in 87% of cases. AI routinely produces PRs that blow past that threshold before a reviewer even opens the diff.
Bryan Finster captures this precisely using signal processing theory: defect detection is a sampling mechanism, and it needs to operate at a frequency that matches the production rate. Manual review is a low-frequency mechanism now paired with high-frequency AI generation. The result is systematic under-sampling. "AI did not eliminate the coding bottleneck," Finster writes. "It just moved it to a different part of the process."
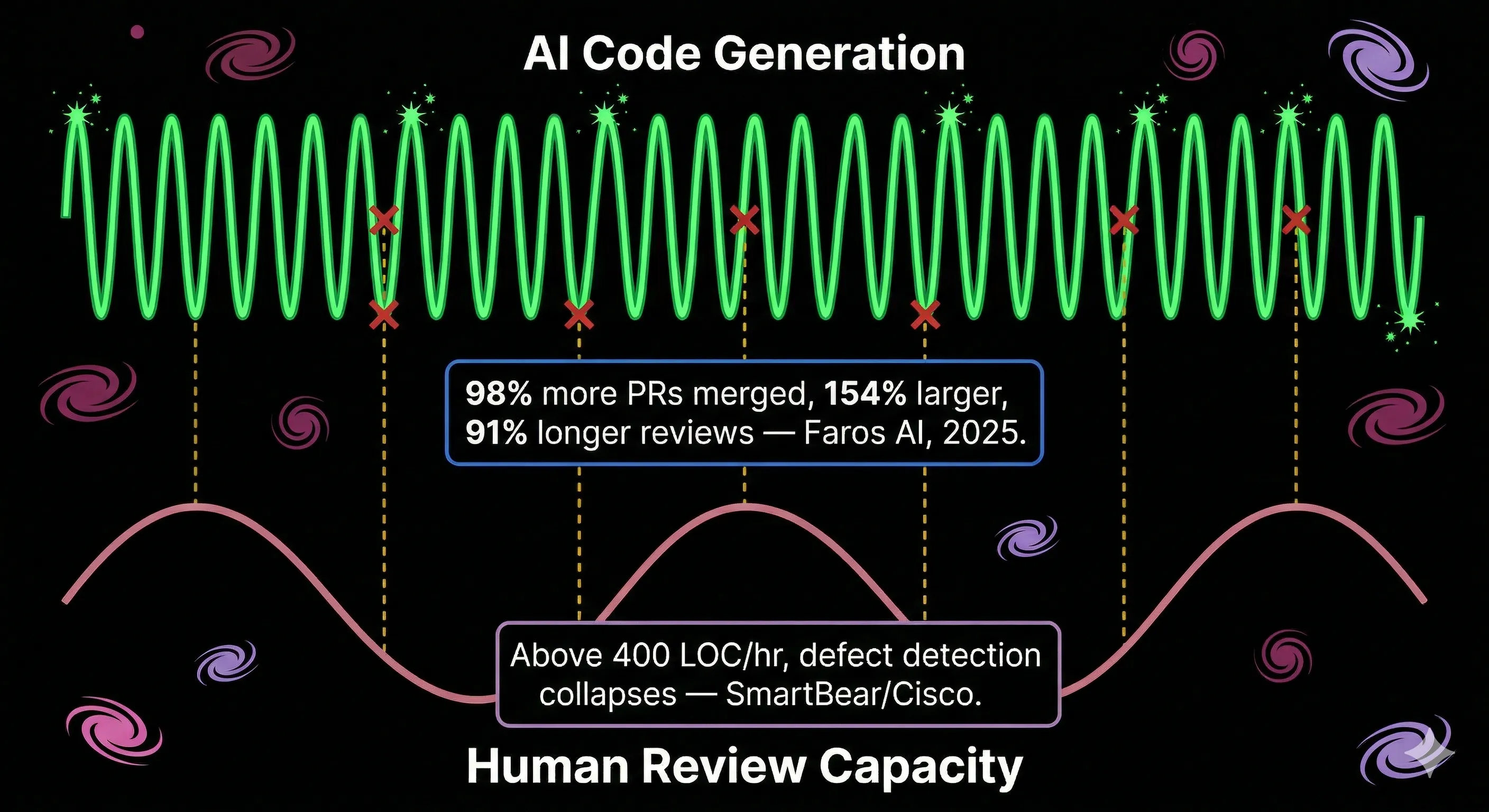
I have seen this play out in practice. When a developer opens a 600-line PR that an agent produced in 20 minutes, the honest review takes longer than the code took to write. Reviewers start skimming. They check the tests, scan for obvious issues, and approve. This is not laziness. It is a rational response to an impossible ask.
The Complacency Trap
This is the part that keeps me up at night, and it is the strongest counterargument to anyone who says "just let AI handle the details."
Research from adjacent fields is clear: when automation is consistently reliable, humans detect only about 30% of errors. When the system sometimes fails visibly, detection jumps to roughly 75%. That is from McBride, Rogers, and Fisk's 2014 study on automation monitoring. Goddard, Roudsari, and Wyatt found that erroneous automated advice is followed at a 26% higher rate than scenarios without automation.
Lisanne Bainbridge formalized this in 1983: "The more reliable the automation, the less the human operator is able to contribute when it fails." The NTSB's investigation into the 2018 Uber autonomous vehicle fatality found exactly this pattern. The human safety monitor stopped paying attention because the system usually worked.
The parallel to code review is direct. If AI review catches 90% of issues, human reviewers may mentally check out for the remaining 10%, which could contain the most critical problems: security vulnerabilities, business logic errors, architectural misalignments.
And confidence makes it worse. Perry et al. at Stanford found that developers who relied on AI for security tasks produced secure code only 12% of the time (versus 29% without AI), yet rated their confidence at 4.0 out of 5 when they had written insecure code. The developers who trusted the AI the most were the ones most harmed by it.
On my team, I have noticed a version of this with junior developers. A January 2026 survey reported by The Register found that developers with under two years of experience report the lowest quality improvements from AI tools (51.9%) but the highest confidence shipping AI code without review (60.2%). Seniors see higher quality gains (68.2%) but are far less confident. The confidence-competence relationship is inverted, and it is a leadership problem that no tool can solve.
What Reviewers Should Actually Be Doing
If line-by-line human review does not scale and automation complacency is real, what is the actual path forward? I have been experimenting with a few frameworks, and the common thread across all of them is the same: humans move upstream.
Define the Contract Before the Code Exists
Addy Osmani (Chrome engineering lead at Google) proposes that every PR in an AI-augmented team should include four things: what and why in one or two sentences, proof it works (tests, screenshots), the risk tier plus which parts were AI-generated, and one or two specific areas where the reviewer should focus. AI handles the 70-80% of low-hanging fruit (null checks, coverage gaps, anti-patterns). Human review focuses on auth, payments, secrets, and untrusted input.
Ankit Jain (CEO of Aviator) takes this further with a five-layer trust system that replaces line-by-line review with layered verification: competitive agent generation, deterministic guardrails, human-defined acceptance criteria, permission-based architecture, and adversarial verification by a separate agent. His key insight: "The spec is not extra work; it is the primary artifact." His team spent two days writing detailed BDD specs, then had an AI agent verify output against 65 acceptance criteria in six minutes.

What I like about both approaches is that they make the reviewer's job explicit. Instead of "review this PR," the ask becomes "evaluate whether this change aligns with the architectural direction and whether the risk areas have adequate coverage." That is a fundamentally different cognitive task, and it is one that humans are actually good at.
Let Machines Own What Machines Do Well
Salesforce built an internal system called Prizm to handle the volume problem at enterprise scale. It uses token-aware chunking, graph-based dependency analysis, and progressive disclosure that surfaces architectural and security changes first. It completes analysis in under five minutes even for large PRs.
GitHub's Copilot code review has conducted 60 million reviews since April 2025. It moved to an agentic architecture in March 2026 that reads PR descriptions, traces cross-file dependencies, and builds repo-level context before commenting. One important design choice: it always leaves a "Comment" review, never "Approve" or "Request changes." It does not count toward required approvals. That is intentional. The tool augments human judgment; it does not replace it.
But here is the honest caveat: the Macroscope 2025 benchmark tested AI review tools against real production bugs and found CodeRabbit at 46% detection, Cursor Bugbot at 42%, Greptile at 24%, and Graphite Diamond at 18%. These tools are useful. They are not reliable. This flags a deeper problem: if both the generation model and review model share similar training data, the review model may be systematically less likely to catch errors the generation model introduced. Using AI to check AI can produce correlated blind spots that are qualitatively different from human reviewer blind spots.
The Nitpick Question
This is where conversations about code review get personal. Every team has the reviewer who leaves 30 comments about variable naming, import ordering, and whether a ternary should be an if-else. And every team has the developer who dreads opening that PR.
I have been on both sides. Early in my career, those detailed reviews taught me more about professional code than any book. Jorge Manrubia of 37signals makes the case that "small stuff when writing code matters, a lot." Detailed feedback about naming, idioms, and patterns represents a "thick middle ground" between what a linter can catch and what an architecture review covers. It transmits institutional knowledge. It is how junior developers learn to write code that belongs in a specific codebase.
But that middle ground is also where review bottlenecks live. And it is where the protective instinct of experienced reviewers can tip into gatekeeping.
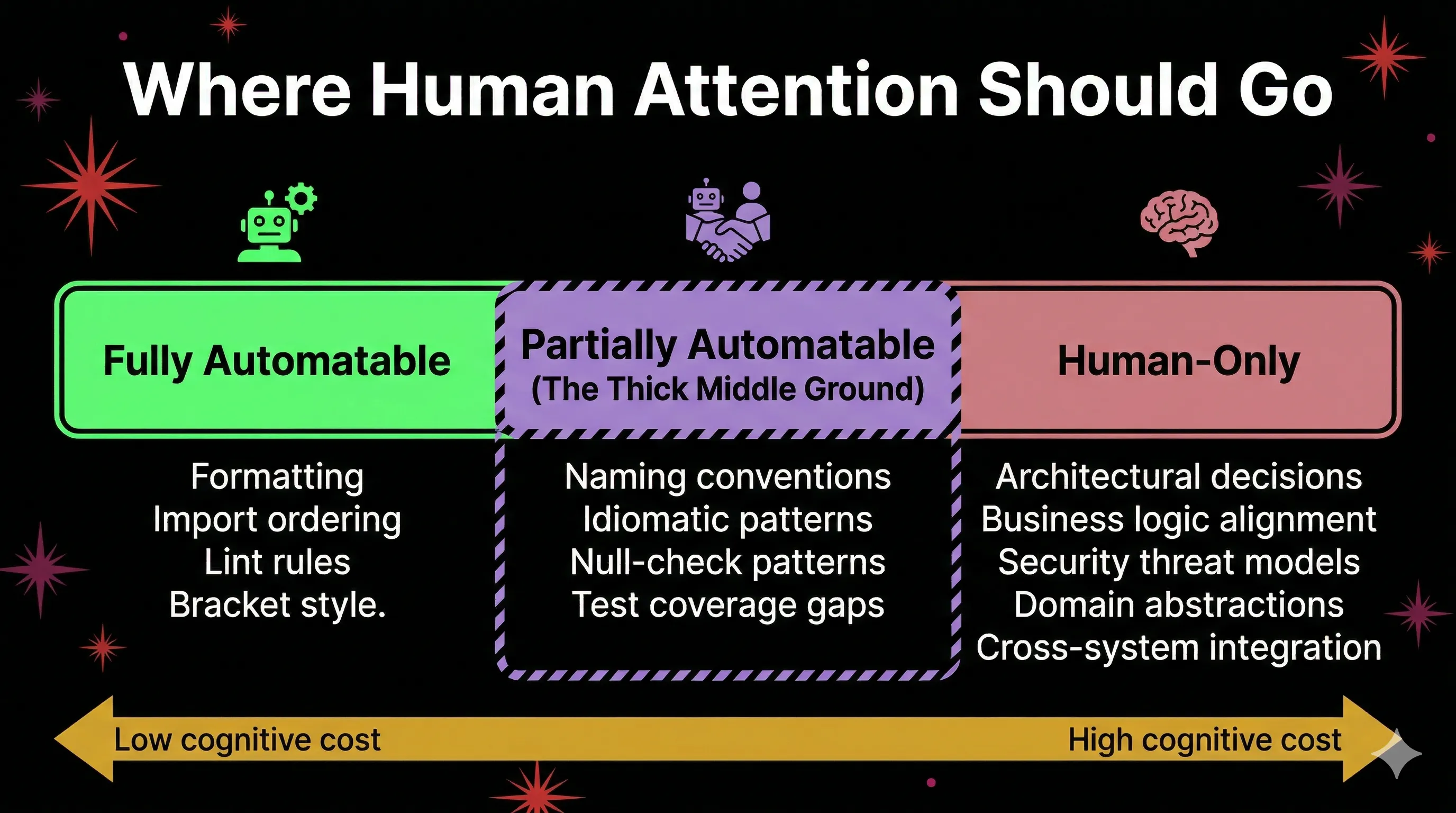
Google's engineering practices offer a pragmatic middle path: allow nitpicks, but prefix them with "Nit:" and never let them block merge. This preserves the teaching function without creating bottlenecks. The reviewer gets to share knowledge. The author gets to ship.
I think this is directionally right, and I would add one thing: automate every nitpick you can, and be honest about which ones you cannot. Modern linters and formatters can own formatting and most style issues. AI review tools can catch null-check patterns and coverage gaps. What remains is the genuinely human layer: does this naming communicate intent to a future reader? Does this abstraction match how the team thinks about the domain? Those are worth a comment. The rest is not worth a human's time anymore.
Where Accountability Actually Lives
The uncomfortable question in all of this: when an incident happens and the postmortem asks "who reviewed this change?", what is the honest answer?
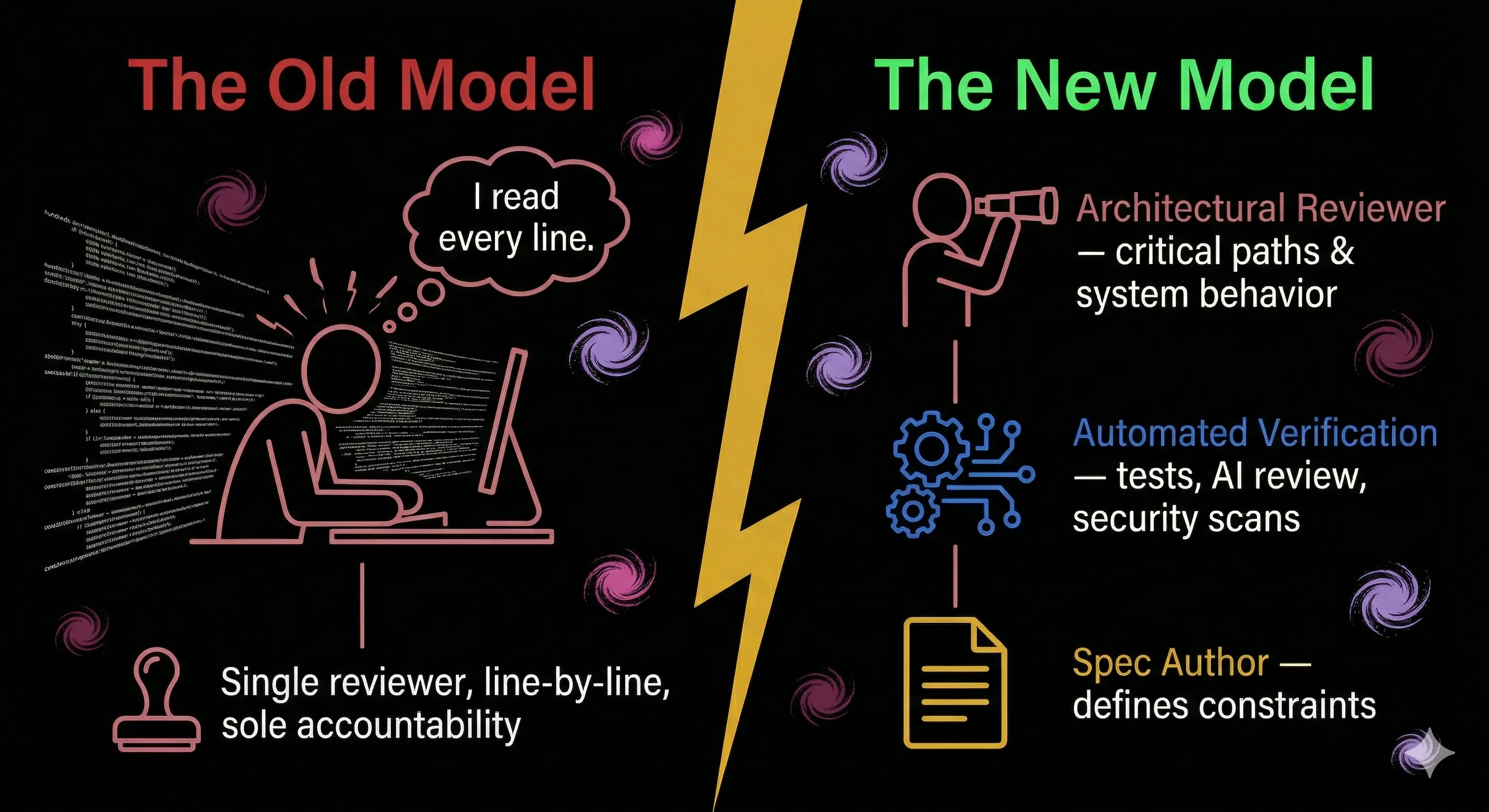
In the old model, the reviewer read the code, understood the reasoning, and approved. That person was accountable. In the emerging model, as IQ Source puts it, the PR submitter pasted output from an AI agent, the reviewer saw code nobody on the team actually wrote, and there was no human reasoning to interrogate because there was none.
The IBM training adage Osmani cites still applies: "A computer can never be held accountable. That is your job."
I do not think the answer is clinging to exhaustive line-by-line review to preserve the illusion of control. The data shows that approach was already failing before AI entered the picture. But I also do not think we can wave accountability away by pointing at test suites and AI review bots.
Here is where I have landed: accountability shifts from "I read every line" to "I defined the constraints, verified the critical paths, and can explain the system's behavior." The reviewer's job is not to catch every bug. It never was. The reviewer's job is to ensure the team understands what shipped and why.
That means investing more time in specifications and acceptance criteria upfront. It means building review checklists that focus on the areas where AI is weakest: security (45% of AI-generated code contains vulnerabilities, and that rate is flat regardless of model sophistication), business domain alignment, and cross-system integration points. It means deliberately exposing your team to AI review failures during training, because Bahner et al. found that exposure to automation failures is one of the few proven countermeasures to complacency.
And it means accepting that we are in a transition period. No longitudinal studies validate the hybrid model yet. The argument for humans doing architecture review while AI handles granular checks is based on reasoning from adjacent evidence, not direct empirical validation. That is an honest gap, and pretending otherwise is how teams end up in the rewrite Jain warned about.
Code review as a universal practice is barely a decade old. The approval gates have moved before. They are moving again. The question is not whether to adapt, but whether you are designing the new system deliberately or just letting the old one quietly break.