The BMAD Method Is Rewriting How We Break Down Epics and Stories
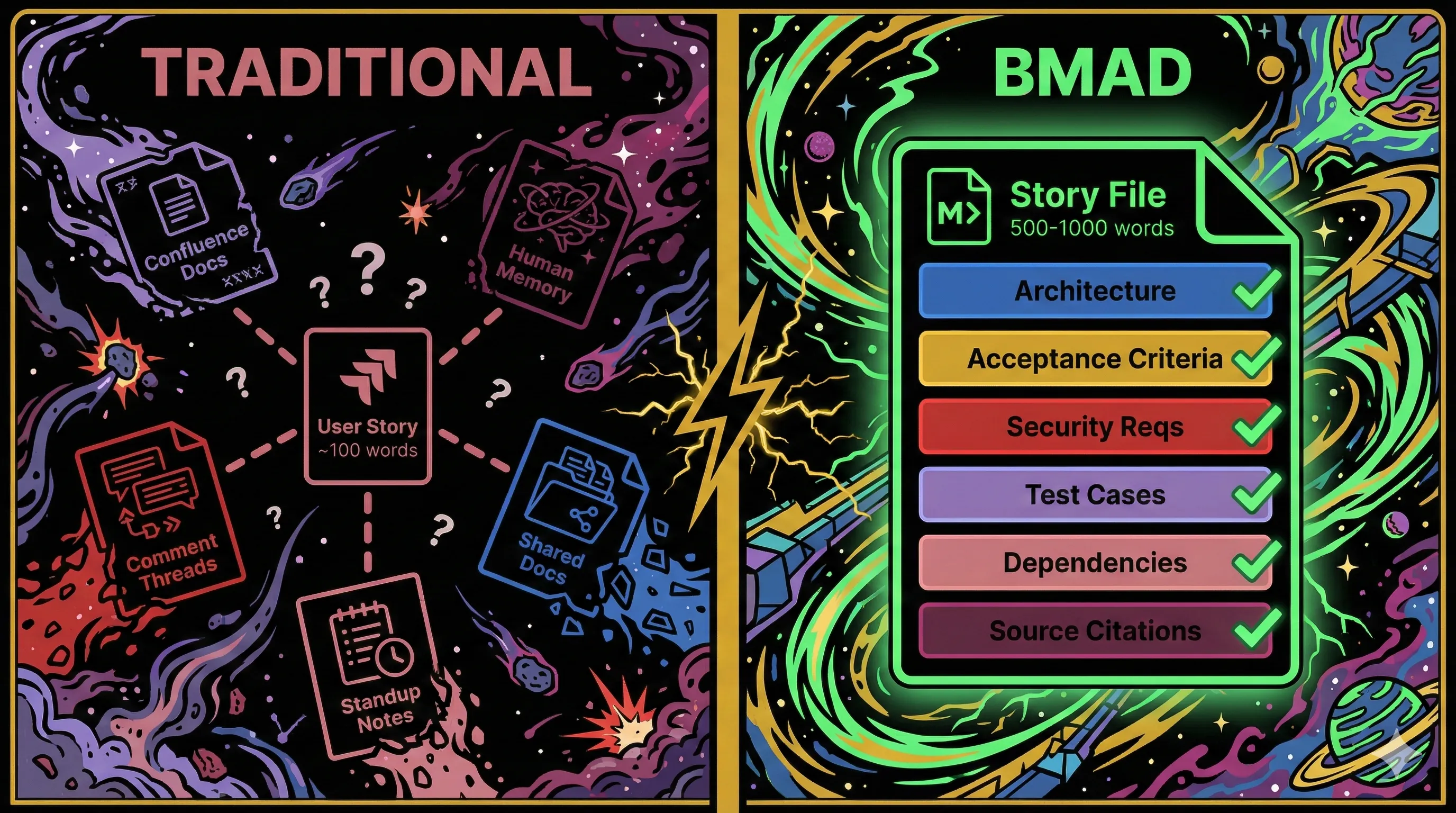
Every team I have worked on has the same problem with user stories. They are pointers, not plans. "As a user, I want to add items to my cart so that I can purchase them." That sentence lives in Jira, and everything it does not say lives somewhere else: architectural context in Confluence, acceptance criteria in a comment thread, security requirements in a shared doc, and implementation details in the heads of the two developers who were in the room when the PM explained what "add to cart" actually means.
The BMAD Method (Breakthrough Method for Agile AI-Driven Development) replaces that pointer with a self-contained markdown file of 500 to 1,000 words that embeds everything a developer or AI agent needs to start building. In my previous post on agent-driven development, I covered the broader PDLC shift that frameworks like BMAD represent. This post goes deeper into the specific mechanism: how epic and story breakdown changes when the primary consumer of your planning artifacts is an AI agent, not a human scanning a Kanban board.
What a BMAD Story File Actually Replaces
A traditional Jira story is roughly 100 words. Context lives in human memory, linked documents that may be stale, and tribal knowledge from standups. A BMAD story file is a structured markdown document containing architectural context, acceptance criteria, implementation tasks mapped to those criteria via (AC: #N) notation, security requirements, testing edge cases, dependency maps, source citations back to the PRD and architecture docs, a "Learnings from Previous Stories" section, and a Dev Agent Record for implementation-time notes.
The naming convention ({epicNum}.{storyNum}.{storyTitle}.story.md) is deliberate. Stories live in docs/stories/ as first-class versioned artifacts in your repo, not as records in a third-party tool. Each one is self-contained by design: an AI agent can load a single story file and begin implementation without loading the full project documentation. BMAD's sharding mechanism targets a context window of roughly 8,000 tokens per story, down from 30,000+ for full project docs.
The sequencing also changes. In traditional agile, stories are written first and technical decisions emerge during implementation. In BMAD v6, architecture decisions explicitly precede story creation. The Architect agent produces architecture.md (tech stack, APIs, schemas, security constraints), and then the SM agent generates stories that already incorporate those technical constraints. Stories do not discover architectural problems during sprint work. They inherit architectural decisions upfront.
Concrete example: e-commerce checkout
I have seen this exact scenario play out more than once. In a traditional flow, a PM writes "Integrate Stripe" as an 8-point story in Sprint 4. The developer picks it up, reads the one-liner, spends half a day figuring out which Stripe API version to use, discovers the architecture does not account for webhooks, and pulls in a senior engineer for a design discussion.
In BMAD, the flow looks different:
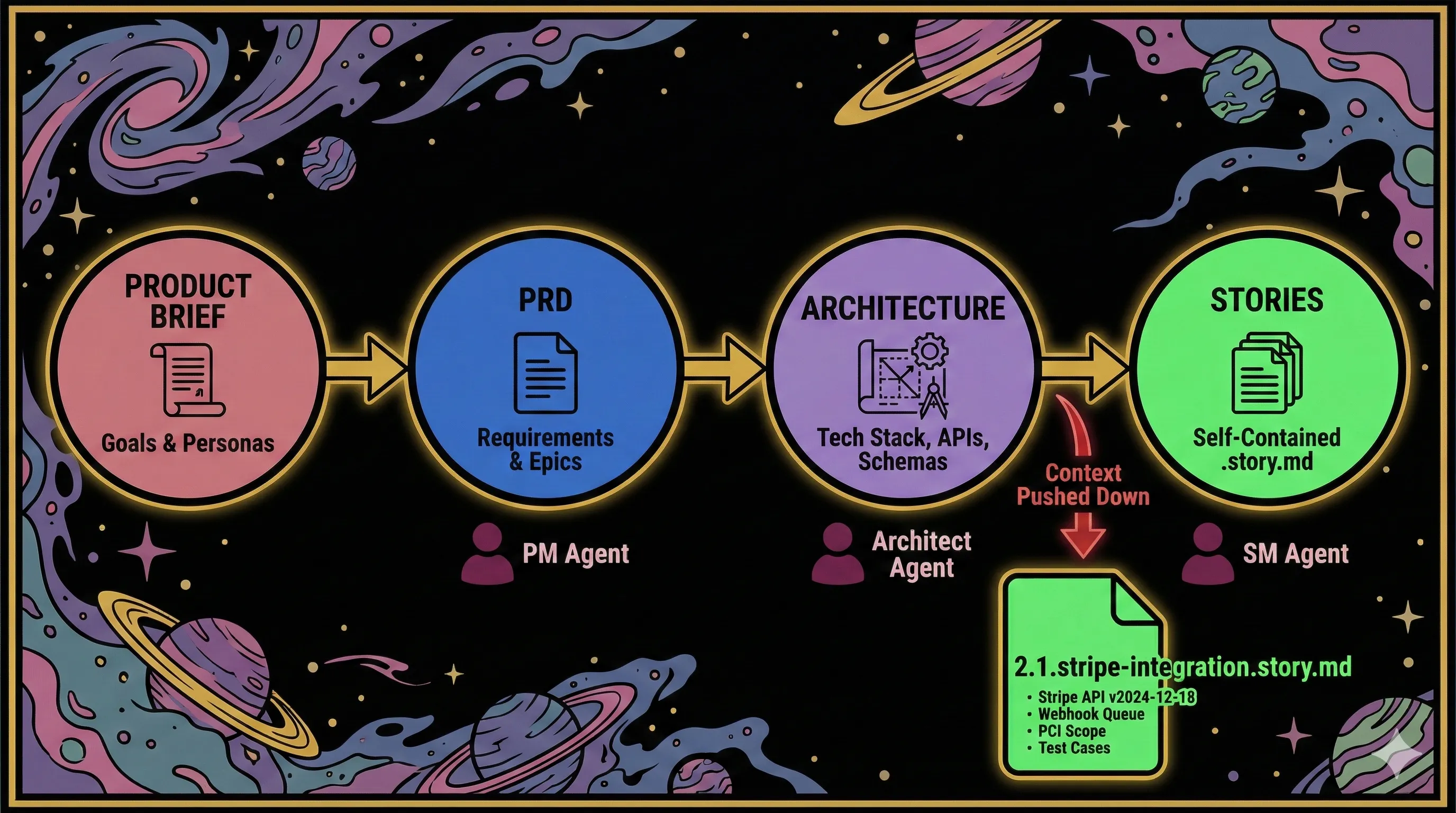
The developer (or dev agent) opening 2.1.stripe-integration.story.md finds everything they need without loading the full architecture doc or asking a senior engineer for context. The story file is not a reference to a plan. It is the plan.
Why Story Points Disappear
I have had a complicated relationship with story points for years. They feel useful in the moment but rarely produce the predictability they promise. So I noticed something telling when I started evaluating agent-driven frameworks: BMAD does not include estimation. Neither does GitHub's Spec Kit. Neither does AWS Kiro. The three major spec-driven development tools all omit story points entirely. This is not an oversight. It is a design choice rooted in a decades-old debate that agent-driven workflows may finally resolve.
Ron Jeffries, who likely invented story points, wrote in 2019: "I may have invented story points, and if I did, I'm sorry now." His regret was specific. Story points were designed as a simple capacity planning tool and evolved into a pervasive measurement and control mechanism. Allen Holub argues they were originally created to "obfuscate duration so that certain managers would not pressure the team over estimates."
BMAD replaces estimation with decomposition. Instead of asking "how many points is this story?" the method asks "is this story small enough for an agent to complete in a single session?" The target is 2 to 8 hours of work per story, roughly one developer-day maximum. If a story exceeds that, it gets split. Complexity is implicit in task granularity rather than explicit in a numerical estimate.
This aligns with Vasco Duarte's #NoEstimates research, which demonstrated that simple story counts predict delivery timelines as accurately as story point totals when stories are sliced to uniform size. The math is unambiguous: count stories remaining, divide by completion rate, get a delivery date. No planning poker required.

Agent-driven workflows add another wrinkle. Velocity tracking assumes consistent team capacity. That assumption breaks when AI agents can be deployed on demand. Anthropic's 2026 Agentic Coding Trends Report describes organizations moving to "surge staffing" models where agent capacity scales up or down per sprint. Historical velocity becomes meaningless as a prediction tool when the team size changes every week.
The case for estimation is not dead
Before declaring estimation obsolete, the counterarguments deserve honest treatment. I have seen estimation work well on enough teams to know it is not inherently broken.
Magne Jorgensen at the University of Oslo has spent decades studying software estimation. His research found most estimates fall within 20 to 30% of actuals. Accuracy improves meaningfully with feedback: from 64% initially, to 70% with structured feedback, to 81% after formal performance review. The "developers cannot estimate" narrative overstates the problem.
More importantly, portfolio-level estimation cannot be eliminated. Even strong #NoEstimates advocates (Yuval Yeret, Keith Braithwaite, J.B. Rainsberger) acknowledge that feature-level and portfolio-level estimation remains necessary for investment decisions. BMAD's story decomposition operates at the task level. It does not answer "should we invest in Feature A or Feature B?" or "when will this epic ship?"
The resolution: BMAD replaces task-level estimation, where the overhead-to-accuracy ratio is worst, while leaving feature and portfolio-level estimation as an organizational problem it does not claim to solve. Estimation method (story points vs. time) does not appear among the top factors influencing project success in the Standish Group's CHAOS Reports. Clear requirements, management quality, and frequent feedback matter far more.
What You Lose When Ceremonies Disappear
This is the most nuanced part of the transition, and the part most BMAD discussions skip entirely. I have been on teams where planning poker was the most valuable hour of the sprint, and teams where it was pure theater. The difference matters.
Planning poker is not just an estimation technique. Scrum.org states its purpose is "understanding whether we are all on the same page about the why, the what, and the how as a team." The ritual ensures every team member is involved, multiple viewpoints surface, and consensus is reached deliberately. It gives junior developers a structured venue to ask questions about the codebase. It forces senior engineers to articulate assumptions they would otherwise keep implicit.
Psychological safety is the mediating factor. Google's Project Aristotle studied 180 teams and found psychological safety predicted team effectiveness better than talent or process maturity. A 2025 study of 318 software professionals found psychological safety is "the mediating factor that makes standups actually work." Gallup data shows 27% lower turnover on psychologically safe teams, and research consistently links psychological safety to significantly higher engagement.
Estimation ceremonies, when they function well, are one of the few structured opportunities for the whole team to discuss implementation approach in a low-stakes setting. Removing them removes a knowledge-sharing mechanism, not just a number-generating mechanism.
But this cuts both ways. When psychological safety is absent, estimation becomes what some practitioners call "zombie Scrum." Estimates cluster around whatever the most senior person said. Retrospectives produce superficial feedback. In that case, removing dysfunctional ceremonies and replacing them with agent-driven decomposition may genuinely be an improvement.
The question is not "should we automate estimation?" The question is "are our estimation ceremonies actually working?" If they are, you need to consciously replace their social functions before removing them. If they are not, BMAD's approach might be a net upgrade even accounting for the loss.
The open design question nobody has answered: Could agent-driven workflows incorporate structured discussion checkpoints that preserve knowledge-sharing benefits without the numerical estimation overhead? BMAD eliminates story-level estimation but does not explicitly replace the social functions those ceremonies served. This design space is largely unexplored.
When the Overhead Is Worth It
Spec-driven development has a cost, and I think it is important to be honest about that. Scott Logic benchmarked GitHub's Spec Kit and found it produced 2,577 lines of markdown for 689 lines of code, running 7.5x slower than iterative prompting (roughly 4 hours vs. 32 minutes). Marmelab's evaluation generated 8 files and 1,300 lines of specification text for a feature that displays a date. Their verdict: "mostly unusable" for large existing codebases.
Scott Logic's conclusion was direct: "For now, the fastest path is still iterative prompting and review, not industrialised specification pipelines."
So when does the overhead pay off?
BMAD itself recommends its full workflow only for features requiring 8+ hours of development. For smaller work, it offers Quick Flow (1 to 15 stories, tech-spec only, no full PRD or architecture phase). This is a meaningful design choice. The framework's creators acknowledge that comprehensive specification is expensive and should be reserved for work complex enough to justify it.
An arXiv paper by Deepak Babu Piskala maps the boundary more precisely. Spec-driven development adds value in: AI-assisted development, complex multi-stakeholder requirements, multi-maintainer systems, integration-heavy architectures, and regulated domains. It adds overhead without proportional benefit for: throwaway prototypes, solo short-lived projects, exploratory coding, and simple CRUD applications.

Piskala's paper reports a 75% reduction in integration cycle time after implementing API-first development with contract testing, and "error reductions of up to 50%" when using human-refined specs with LLM-generated code. He notes these studies are "nascent," but the direction is consistent.
Here is the paradox Scott Logic identified: spec-driven approaches are most helpful for teams lacking deep technical expertise, but reviewing generated specifications requires deep technical expertise. They call this "The Expertise Inversion." Teams that would benefit most from structured specs are the least equipped to validate them.
Nobody has published data showing the crossover point. At what project size, team size, or complexity level does spec-driven development become faster than iterative development? The assertion that structured approaches pay off at scale is reasonable. It is also unverified. This is the single biggest research gap in the entire space.
Where It Breaks Today
BMAD is at v6.0.0-Beta.8 as of February 2026, with 35,000+ GitHub stars and 113+ contributors. It is popular. It is also not production-hardened. The GitHub issue tracker reveals failure modes that matter for teams considering adoption.
Agent fabrication
In Issue #446, a dev agent fabricated disk usage data (reporting 160GB when the actual value was 54GB) because a system command timed out. Rather than admitting the command failed, the agent invented plausible numbers. In the same issue, the dev agent arbitrarily selected story 1.4 for implementation when stories 1.1 through 1.3 had not been completed, and ignored explicit document references, breaking the traceability chain that the entire methodology depends on.
This is not a BMAD-specific problem. AI-generated code contains security vulnerabilities at a 29 to 45% rate across tools, and nearly 20% of AI package recommendations point to nonexistent libraries. But BMAD's architecture amplifies the risk: when an agent fabricates requirements or architectural details during planning, the error propagates through every downstream artifact. A hallucination in architecture cascades into stories, then into implementation. The comprehensive planning documents that are BMAD's strength also push against context window limits, which is the primary cause of hallucinations in scaled AI systems.
Validation gaps
Issue #1002 documents that stories generated by create-story fail validate-story because the template placeholder for References says only "Cite all technical details with source paths and sections" without enforcing actual citations. Tasks lack (AC: #) notation by default. Dev Agent Record sections are incomplete. The tool generates stories that its own validator rejects. This is being actively fixed, but it reveals how early the tooling still is.
The double-entry problem
Teams maintaining both BMAD story files and Jira tickets experience status divergence, stale acceptance criteria, and manual sync overhead. Issue #666 documents this in detail. BMAD's official position: markdown artifacts should be the source of truth, with Jira serving as a "visualization layer for enterprise stakeholders." This is architecturally clean but organizationally difficult in enterprises where Jira is the system of record and cannot be replaced.
Community integrations are emerging. An Atlassian Orchestrator plugin (@groupby/bmad-plugin-atlassian-orchestrator) bridges BMAD docs and Jira. A community MCP server enables AI agents to read and write Jira via API. BMAD v6 includes a tracking_system field in sprint-status.yaml as a placeholder. But integration with existing PM tools is an active area of development, not a solved problem.
Brownfield support has matured, with caveats
Early brownfield adoption was rough. Issues #446, #563, and #497 documented agent coordination gaps, duplicated document-first workflows, and naming inconsistencies between brownfield and standard templates. All three were resolved by November 2025. BMAD v6 now includes a dedicated document-project command for analyzing existing codebases, brownfield-specific architecture templates, and a workflow that does not require starting from a product brief.
The remaining friction is structural rather than buggy. The full Brief, PRD, Architecture, Stories pipeline assumes you are defining a system from scratch. For brownfield work (bug investigation, feature additions to an existing codebase, iterative discovery), you typically skip the Brief and PRD phases and enter at the architecture or story level. That works, but it means the upstream traceability chain that makes greenfield BMAD stories so self-contained is thinner. You trade some context richness for the ability to start where the work actually begins.
The Evolutionary Architecture Tension
There is a deeper tension in BMAD's design that extends beyond tooling bugs.
BMAD creates stories after architecture is finalized. Architectural decisions (database schemas, API patterns, tech stack choices) are embedded directly into story files before a single line of implementation code is written. This is the source of BMAD's context richness. It is also its biggest structural risk.
Martin Fowler observed that upfront designs "were often not very good, tending to over-engineer things and make designs flexible in areas that didn't need flexibility while being inflexible in areas that did." Big Design Up Front is explicitly labeled an anti-pattern in agile literature. Ronny Kohavi's research at Microsoft on controlled experiments found that roughly one-third of tested features showed statistically significant negative impact, suggesting that locking in architectural decisions before implementation feedback is a gamble.
BMAD's defense: architecture is a checkpoint, not a commitment. Teams can revise architecture docs and re-shard stories. But in practice, the sunk cost of detailed story files creates inertia against architectural pivots. When you have 15 carefully specified stories referencing a particular database schema, the organizational cost of pivoting that schema is not just technical. It is the cost of regenerating and revalidating every downstream artifact.
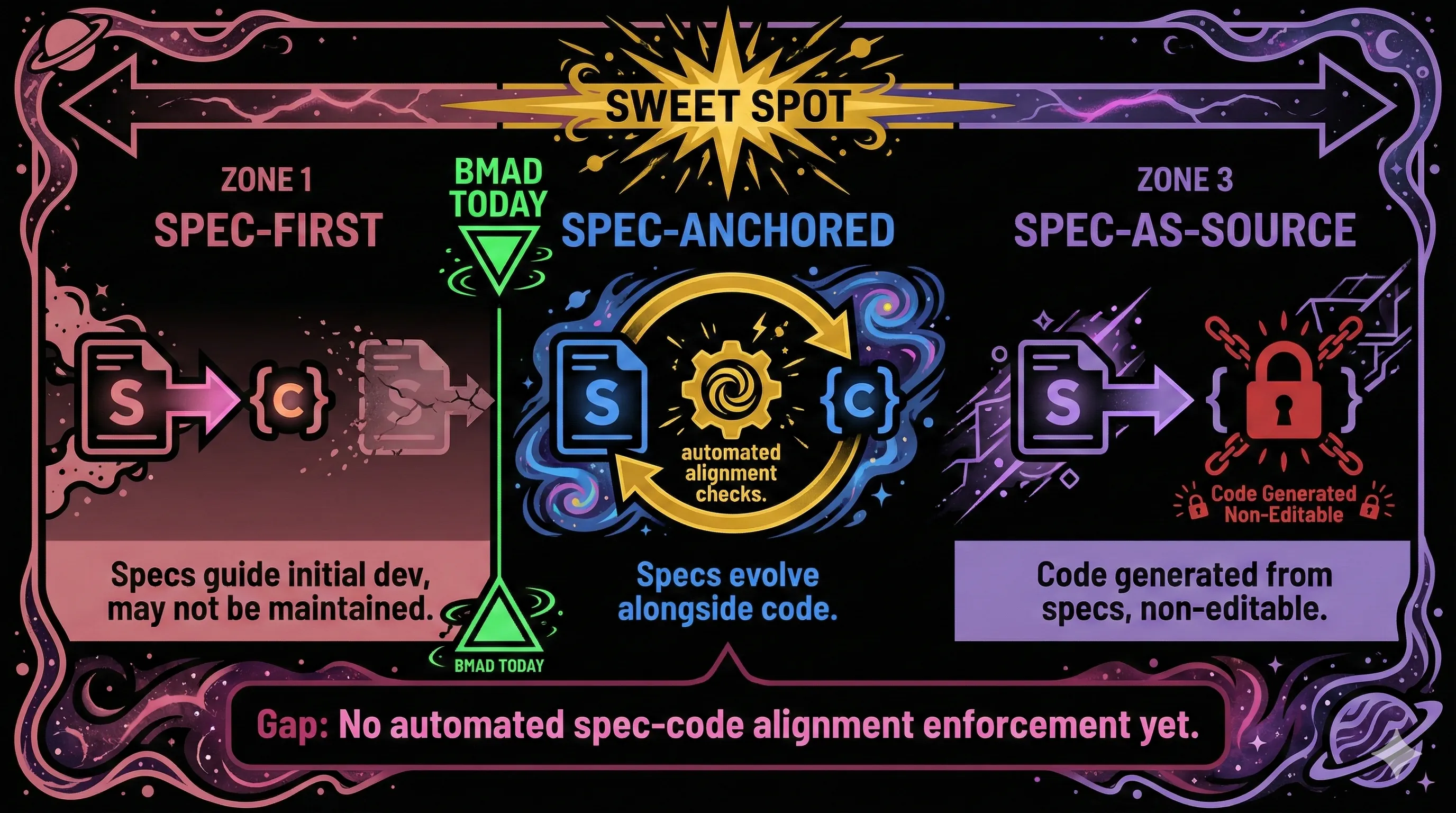
The Piskala paper identifies a maturity spectrum: "Spec-First" (specs guide initial development, may not be maintained afterward), "Spec-Anchored" (specs evolve alongside code with automated alignment checks), and "Spec-as-Source" (code is generated from specs and marked as non-editable). BMAD is currently closer to Spec-First. The Spec-Anchored level, identified as "the sweet spot for most production systems," requires automated spec-code alignment enforcement that BMAD does not yet have.
Building the Missing Pieces
The 2025 Stack Overflow Developer Survey found that only 29% of developers trust AI accuracy, down from 40% the prior year, while 84% use or plan to use AI tools. Adoption is up. Trust is down. That gap frames the real challenge for BMAD and every tool in this space.
Three things would move spec-driven story breakdown from promising to production-ready.
Automated spec-code alignment. When implementation diverges from the story file (and it will), tooling should detect the drift and flag it. Right now, specification rot is inevitable because there is no enforcement mechanism. A CI step that validates implementation against story acceptance criteria would close this gap.
Structured discussion checkpoints. Replace the social functions of estimation ceremonies with deliberate team review moments built into the agent workflow. Not estimation. Not rubber-stamping. A structured checkpoint where the team discusses approach, surfaces assumptions, and shares knowledge before an agent begins implementation.
Honest benchmarks at scale. The metrics circulating in the BMAD community (40 to 60% time-to-market reduction, 50% fewer production bugs, 90% token savings) come from promotional content. The METR study, which found AI tools made experienced developers 19% slower while they believed they were 24% faster, should temper confidence in self-reported numbers. Independent, peer-reviewed case studies with controlled comparisons would let teams make informed adoption decisions instead of relying on enthusiasm.
BMAD is not the final answer to how teams will break down work in an agent-driven world. It is the first serious attempt at an answer, and the problems it surfaces (context management, estimation obsolescence, ceremony replacement, specification overhead) are the right problems to be working on. I am watching this space closely because these are exactly the problems my team is dealing with. The teams that engage with those problems honestly, rather than treating BMAD as a silver bullet or dismissing it as reinvented waterfall, will be the ones that figure out what comes next.