The Era of Humans Writing Code Is Over. Now What?
I have been managing engineering teams through the AI transition for over a year now, and I still cannot tell you whether it is making us better or just making us faster at the wrong things. So when Ryan Dahl posted in January that "the era of humans writing code is over," my first reaction was not shock. It was exhaustion. We have heard this before. But then I sat with it, and something about this particular declaration landed differently.
This post is about why Dahl's statement matters more than the dozens that came before it, what the data actually shows about AI-assisted development in early 2026, and what it means for the engineering teams, processes, and career paths that were built around humans writing code by hand.
The CEO Chorus vs. the Practitioner
Every few months, a tech leader declares coding is dead. Jensen Huang told a GTC audience in 2023 that "everyone is a programmer now." Dario Amodei predicted in March 2025 that AI would write 90% of code within three to six months. Satya Nadella said 20-30% of Microsoft's code was already AI-written. Tobias Lutke told Shopify teams they must prove AI cannot do work before hiring a human.
I have tracked these predictions since 2023, and the pattern is consistent: bold claims, partial delivery, then a quiet recalibration.
 By end of 2025, 41% of code was AI-generated, not 90%. Amodei's timeline passed without materializing at industry scale, though Anthropic's CPO claimed it came true internally.
By end of 2025, 41% of code was AI-generated, not 90%. Amodei's timeline passed without materializing at industry scale, though Anthropic's CPO claimed it came true internally.
So why does Ryan Dahl's version hit differently?
Because Dahl is not selling AI products. He is the practitioner who created Node.js after Chrome's V8 engine shipped in 2008, then gave the famous "10 Things I Regret About Node.js" talk at JSConf EU 2018, publicly criticizing his own design decisions, and built Deno to fix them. His opinion comes from decades of systems-level programming. When the creator of the runtime that powers half the web says coding is over, the credibility calculus is different than when a CEO says it at a keynote while selling GPUs.
And Dahl added a critical nuance that most headlines buried: "That's not to say SWEs don't have work to do, but writing syntax directly is not it." He is not predicting unemployment. He is predicting a job description rewrite.
He is not alone among practitioners. Boris Cherny, creator of Claude Code, told Y Combinator's Lightcone podcast that "coding is practically solved for me, and I think it'll be the case for everyone regardless of domain." He said he shipped 22 PRs in a day and 27 the day before, each one 100% written by Claude. Andrej Karpathy reversed his own "vibe coding" framing, calling it "passe" and saying agents now write code "99 percent of the time."
The shift from executive prediction to practitioner testimony is what makes this moment different.
What the Numbers Actually Show
I wrote in my first post about agent-driven development that my team's productivity gains from AI tools have been "genuinely confusing." The industry data explains why.
Adoption is massive, trust is not
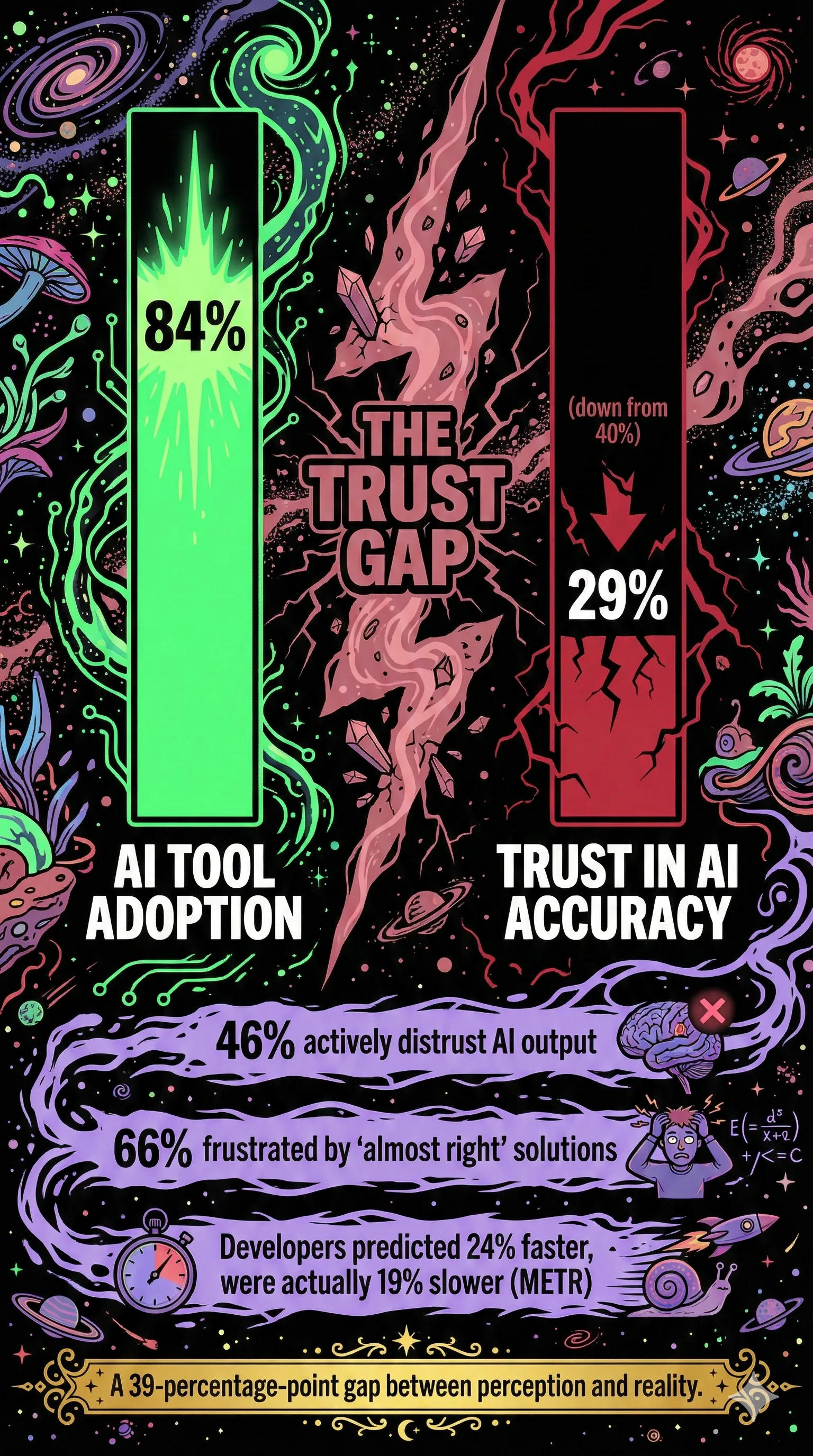
The 2025 Stack Overflow Developer Survey found that 84% of developers use or plan to use AI coding tools. Jellyfish reports 90% of engineering teams now use AI in their workflows. This is real. It is happening.
But buried in the same Stack Overflow survey: only 29% trust AI accuracy, down from 40% the prior year. 46% actively distrust AI output. The number one frustration, cited by 66% of developers, is "AI solutions that are almost right, but not quite."
I recognize a version of this on my own team, though the shape is different. My engineers genuinely enjoy these tools and are moving measurably faster with them. The trust gap is not the problem in our case. The problem is that the speed they unlock does not fit inside a traditional PDLC structure. 84% adoption, 29% trust is the industry story. On teams where trust is high, the gap shifts: it is not between adoption and belief, but between velocity and the processes designed to govern it. That is where the real problems live.
The perception-reality gap
This is the datapoint that changed how I think about measuring AI's impact. METR ran a randomized controlled trial with 16 experienced open-source developers on 246 real tasks in repos averaging 22,000+ stars and over a million lines of code. The developers were 19% slower with AI tools. But before the study, they predicted AI would make them 24% faster. After the study, they still believed AI had sped them up by 20%.
A 39-percentage-point gap between perception and reality. I referenced this study in both my previous posts because it is the single most important datapoint for anyone managing an AI transition. You cannot rely on self-reported productivity. You have to measure outcomes directly.
The METR study has caveats (small sample, deeply expert developers with an average of 5 years and 1,500 commits in their repos), but the pattern recurs everywhere. Cortex found PRs per author up 20%, but incidents per PR up 23.5%. CircleCI's 2026 report showed feature branch throughput up 15%, but main branch throughput down 7%, with main branch success rates at a five-year low of 70.8%. Only 1 in 20 teams achieved balanced growth across both speed and stability.
We are generating more code. We are not shipping more reliable software.
The Real Job Description
If Dahl is right and syntax-writing is ending, what do software engineers actually do?
I have been watching my own role change over the past year. Cherny put the trajectory bluntly: "I think we're going to start to see the title 'software engineer' go away. And I think it's just going to be maybe builder, maybe product manager, maybe we'll keep the title as a vestigial thing." On his team, engineers are already spending their time writing specs and talking to users instead of writing code. Nicholas Zakas, creator of ESLint, maps the same arc: AI as autocomplete (2024), engineer as conductor (2025), engineer as orchestrator managing parallel AI workstreams (late 2025 onward).
"The job becomes less about delivering code and more about delivering value." That matches what I have seen. My best engineers are not the ones who type fastest. They are the ones who define problems most precisely and catch errors in AI output most reliably.
Addy Osmani at Google frames it as the "force multiplier" model: treat AI as "a fast but unreliable junior developer who needs constant oversight." In his observation, developers succeeding with AI spend 70% of their time on problem definition and verification, 30% on execution. The traditional split was roughly inverted.
This is what I described in my post on agent-driven development as the PDLC redesign: moving from a process built around humans writing code to one built around humans orchestrating agents. The work shifts from implementation to architecture, security review, and quality validation. Addy Osmani captures the core tension: AI writes 80% of the code, but the remaining 20% is where the hard engineering lives. Error handling, security, performance, testing, architectural decisions, accessibility. "Software quality was never primarily limited by coding speed."
What this looks like in practice
On my team, the daily work for a senior engineer increasingly looks like this:
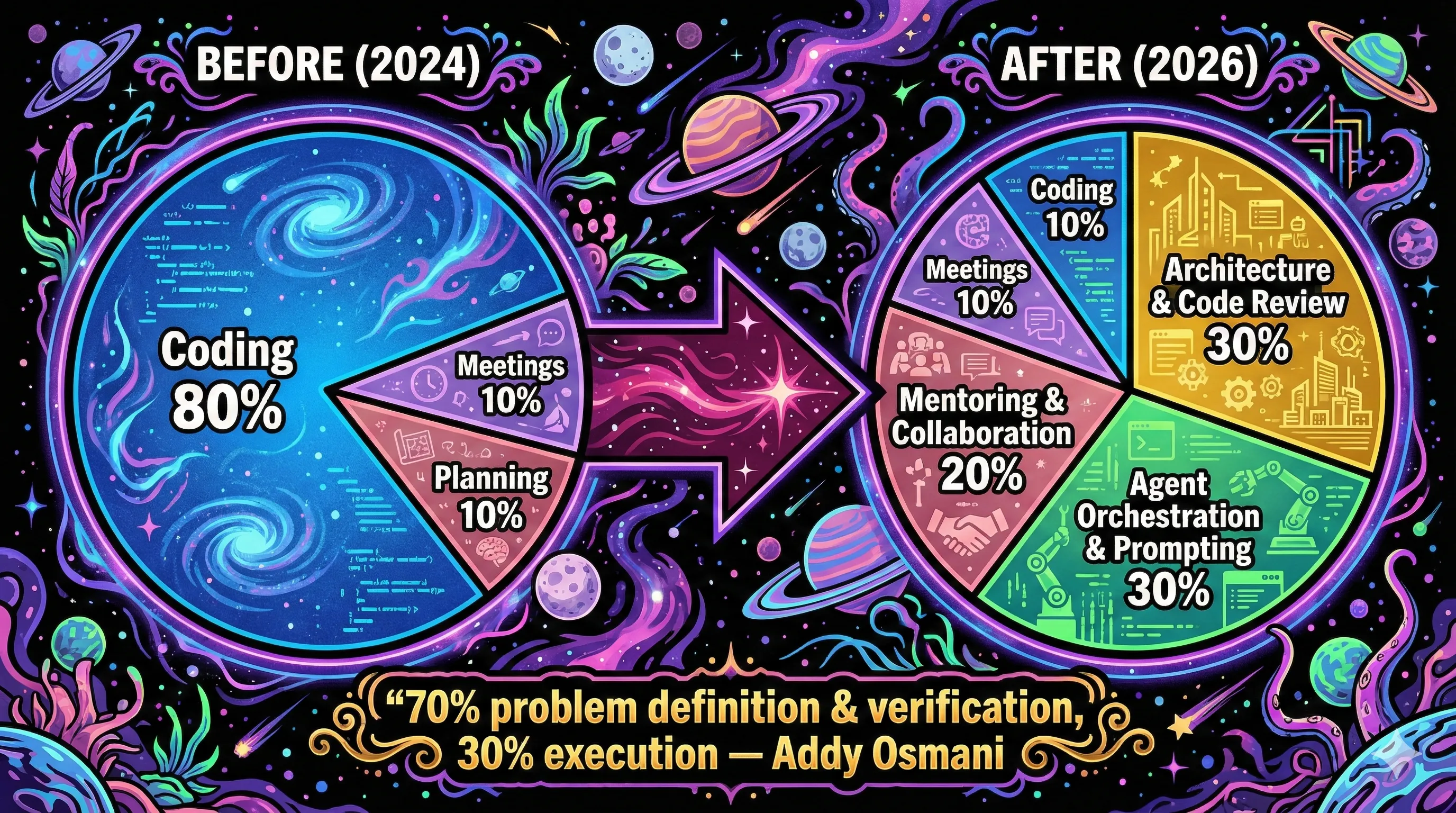
That is not a theoretical model. It is the pattern I see playing out. Cherny takes it further: on his team, "every single function codes" — product managers, designers, engineering managers, even finance. They hire mostly generalists rather than specialists, because "the model can fill in the details." But that raises a question that keeps me up at night.
The Junior Developer Crisis
If senior engineers are shifting from coding to orchestrating, who trains the next generation of senior engineers?
This is the most alarming finding across everything I have read in the past six months. A Harvard study analyzing 62 million workers across 285,000 firms found that junior employment fell 7.7% in AI-adopting firms relative to non-adopters within six quarters. Senior employment remained largely unchanged. Software developers aged 22-25 saw employment fall nearly 20% from their late-2022 peak.
The pipeline is collapsing from multiple directions:
- Tech internship postings declined 30% since 2023
- 70% of hiring managers believe AI can perform intern-level work
- 54% of engineering leaders plan to hire fewer juniors due to AI efficiencies
- Computer engineering graduates face 7.5% unemployment, nearly double the national average
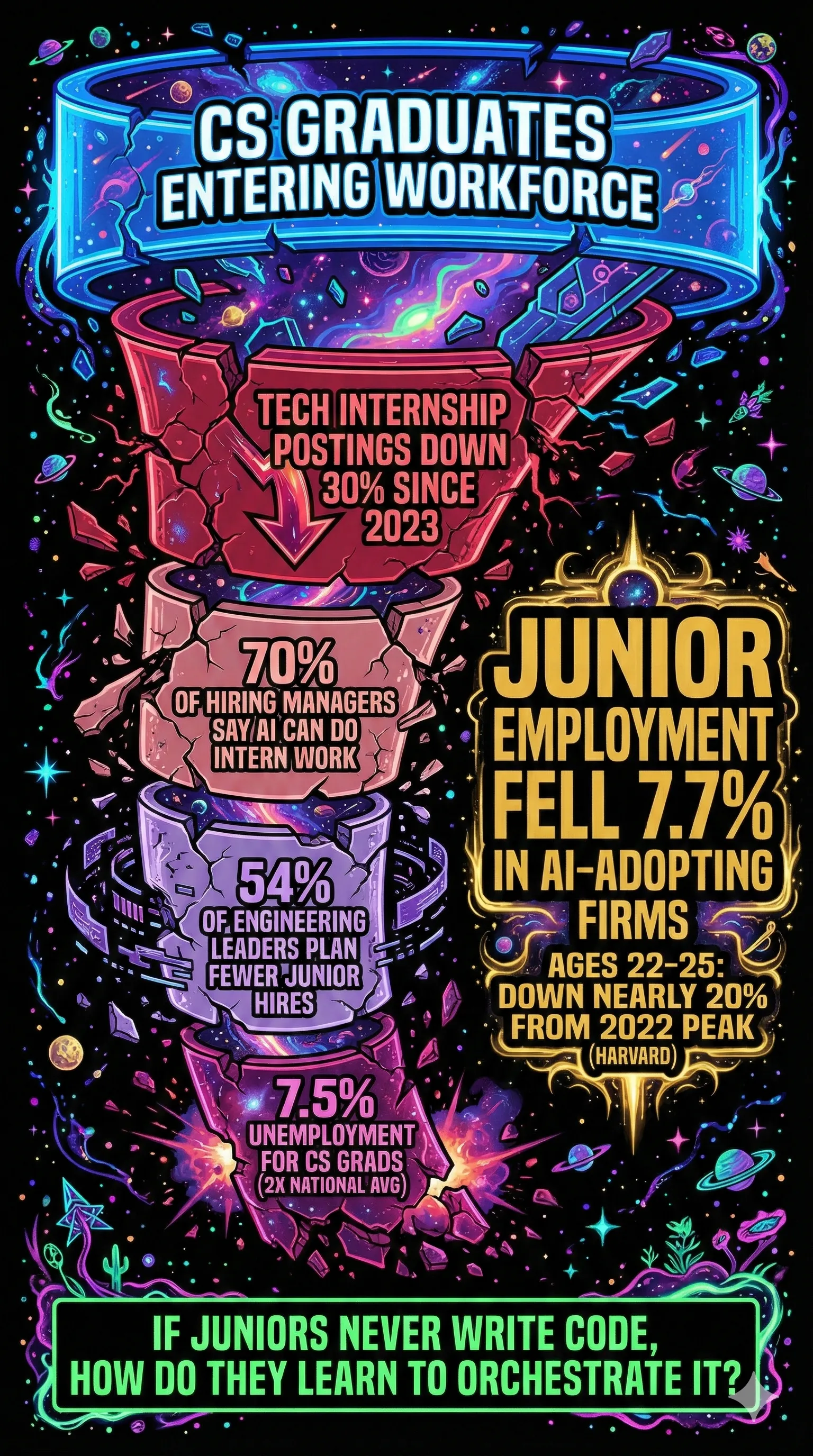
I asked in my BMAD post what happens to knowledge transfer when estimation ceremonies disappear. Dahl's statement raises the same question at a larger scale: if juniors never write code, how do they learn to orchestrate it? The skills that make a great orchestrator (architecture intuition, debugging instinct, knowing what "wrong" looks like) are skills developed through years of writing code and making mistakes.
The Air France 447 problem
There is a direct parallel in aviation. In 2009, Air France Flight 447 crashed when its pitot tubes froze and the autopilot disengaged over the Atlantic. The pilots could not manually fly the aircraft at high altitude. Air France had already identified in an internal report that airmanship skills were weak. 228 people died. Aviation researchers documented this as "automation complacency", the degradation of manual skills when automation handles routine operations.
I keep coming back to this analogy because the dynamic is identical. We are building systems where AI handles the routine coding, but the moment something goes genuinely wrong (a novel security vulnerability, an architectural failure under load, a production incident with no clear cause), we need engineers who understand the fundamentals. If we stop training engineers on fundamentals, we will not have them when it matters most.
Addy Osmani flags this directly: 84% of developers use AI regularly, and entry-level coders are skipping fundamentals like implementing algorithms or debugging memory leaks independently. The industry is eliminating the training pipeline while increasing the need for the skills that pipeline produces.
The Debt We Are Building
The speed of AI code generation is real. So is the debt it creates.
GitClear analyzed 211 million changed lines across Google, Microsoft, Meta, and enterprise repos. Code duplication blocks (5+ identical lines) increased 8x during 2024. Copy/paste exceeded refactored ("moved") code for the first time in recorded history. Code churn (new code revised within two weeks) rose from 3.1% in 2020 to 5.7% in 2024.
AI generates code by pattern matching against training data. It does not refactor. It duplicates. And that duplication compounds.

Security is worse, not better
The security data is blunt. Veracode's 2025 report found 45% of AI-generated code contained security flaws. Java was worst at 70%+. CodeRabbit found AI pull requests averaged 10.83 issues vs. 6.45 for human PRs, with 2.74x more XSS vulnerabilities. Georgetown's CSET reported a 29-45% vulnerability rate across tools, with roughly 40% of Copilot-generated programs vulnerable to CWE Top 25 weaknesses.
Then there is slopsquatting: roughly 20% of AI code samples recommend packages that do not exist. 43% of those hallucinated names are consistently repeated, making them exploitable. Attackers register the fake package names with malicious code and wait.
In fintech, where I work, these are not abstract risks. They are audit findings and regulatory exposure.
The generation-to-shipping gap
CircleCI quantified the distance between "AI can write code" and "AI can ship reliable software." For a team pushing 5 changes daily at 70% main branch success (the current average) vs. 90% (the historical benchmark), the gap costs roughly 250 hours per year. At 500 changes per day, that equals 12 full-time engineers lost to remediation.
Ana Bildea captured the dynamic: "Traditional technical debt accumulates linearly. AI technical debt is different. It compounds." Senior practitioners are converging on 2026-2027 as when accumulated AI-generated debt will reach crisis levels. Organizations risk "systems they cannot understand within 18 months."
What This Means for Your PDLC
This is where Dahl's statement connects to everything I have been writing about. If humans are not writing code, then every process built around humans writing code needs to change. Not just the tools. The lifecycle.
I laid this out in detail across my first post on agent-driven development and my deep dive into BMAD's story breakdown, but here is the summary of what is shifting:
Sprint planning becomes story sharding. Traditional two-week sprints assumed human-speed iteration. When AI agents can scaffold a feature in an afternoon, the planning unit shrinks. The BMAD Method replaces estimation with decomposition: stories targeting 2-8 hours each, tracked by count (stories remaining / completion rate = delivery date) instead of story points. As I wrote previously, Ron Jeffries, who likely invented story points, has said he regrets it.
Code review becomes multi-layer validation. When AI generates most of the code, review is not about style preferences. It is about correctness, security, and architectural alignment. Faros AI found that high-adoption teams merge 98% more PRs, but review time increases 91%. In fintech, this is a compliance bottleneck.
Agile principles are under pressure, but not dead. "Individuals and interactions over processes and tools" gets complicated when the tool becomes a team member generating most of the code. "Working software over comprehensive documentation" gets complicated when spec-driven approaches like BMAD produce 2,500+ lines of markdown for a few hundred lines of code. But the need for short feedback loops, human review, and iterative validation becomes more important, not less.
The failure is organizational, not technical. Scrum.org analyzed 166 AI transformation anti-patterns and found 65% are organizational failures (governance, roles, process, culture). Only 22% are technical. The tools work. The organizations have not caught up.
The Historical Pattern, and Why This Time Might Be Different
I would be dishonest if I did not acknowledge: we have been here before. COBOL promised in the 1950s that human-like text would eliminate programmers. By 2020, 90% of Fortune 500 companies still ran it, and governments were pleading for COBOL developers. Every generation of abstraction (assembly to high-level languages, procedural to OOP, to web frameworks, to no-code/low-code) was predicted to kill programming. Each time, the number of programmers grew because demand expanded faster than automation could absorb it.
Andrew Ng argues this pattern will hold: "As coding becomes easier, more people should code, not fewer!" Grady Booch, co-creator of UML, sees a "third golden age" of software engineering focused on systems-level thinking, noting current AI tools have "mostly been trained upon a set of problems that we have seen served over and over again." They excel at web CRUD. They cannot handle the frontier of computing.
But the counterargument deserves honest treatment. Previous abstractions still required humans to specify precise logic. AI tools accept natural language and generate implementations. Tim O'Reilly connects this to economist James Bessen's research on textile mills: when looms were mechanized, skilled crafters were displaced, but factory workers still needed different skills. Wages remained flat for 50 years because knowledge about effectively using new technology dispersed slowly.
That is the most honest framing I have found. This is probably not the end of software engineering. But it may be a 50-year wage stagnation if we handle the transition poorly.
What to Do Now

If you lead an engineering team, here is what I am doing and what the data supports.
Measure outcomes, not activity. The METR perception gap means self-reported productivity is unreliable. Track what ships to production, how stable it is, and how long incidents take to resolve. Not how many PRs get merged or how many lines of code get generated.
Retrain your junior pipeline around the senior mindmap. The most valuable thing a senior engineer brings is not syntax fluency. It is a decision architecture: what questions do I ask when I start a review? Why those questions? What failure modes am I defending against? What is the blast radius if this goes wrong? That layer of abstraction is where the value is moving, and it is what we should be training juniors on. Use AI code review as a training vehicle: hand a junior an AI-generated PR and ask them to find what it missed. That exercises exactly the judgment muscle they need. Keep targeted fundamentals exercises for building the pattern recognition that powers those decisions, the way medical residencies use structured simulation alongside clinical reasoning frameworks. The DORA research shows that dedicated learning time produces 131% more adoption than mandates. Apply the same principle, but aim the learning at decision-making, not syntax.
Start asking hard questions about your PDLC. I will be honest: my organization has hit a brick wall here. My immediate team is following a lot of what I have been advocating for, and the results are encouraging. But getting an entire organization to adopt a restructured PDLC is a different problem entirely. I laid out a phased rollout in my first post, and the theory still holds, but organizational adoption runs into office politics, competing priorities, and the inertia of processes that feel safe because they are familiar. If you are still running two-week sprints with Jira story cards and planning poker as if nothing has changed, you are accumulating organizational debt alongside the technical kind. But convincing leadership and adjacent teams to change when the current process is not visibly broken yet is a different kind of engineering problem, one that no framework can solve for you. From every conversation I have had with peers at other organizations, everyone is stuck in the same place. Nobody has this solved. The best I can offer is: start the conversation now, before the process breaks on its own terms.
Name the trust gap, then solve it with containment. Your developers are using tools they do not trust. Organizations with clear AI acceptable-use policies see 451% more adoption than those without. But policies alone do not address the underlying fears: what if the AI destroys something in my environment, leaks client data, or introduces a security breach? Isolated dev environments in addition to policy can help. Running Claude inside a Docker container with proper firewall rules and filesystem isolation neutralizes the biggest trust blocker at the infrastructure level. The container becomes the guardrail, so the AI does not need fifteen other guardrails slowing it down. Every permission prompt is a context switch, and containment eliminates most of them. In my experience, this is where productivity starts to go through the roof: not by removing human oversight, but by moving it to where it belongs. Containment lets you shift human review from execution-time to review-time. Let the AI run freely in its sandbox, then review the output at the PR gate. The human is still in the loop for the things that matter (correctness, security, architectural alignment) without hovering over every keystroke.
Budget for the debt. GitClear's 8x duplication increase and Veracode's 45% vulnerability rate are not theoretical. They are showing up in your codebase right now. Allocate engineering time specifically for AI-generated code review, refactoring, and security remediation.
Ryan Dahl is probably right that the era of humans writing code, in the traditional sense, is ending. But the era of humans being responsible for what code does, how it performs, and whether it can be trusted is not going anywhere. The engineers and organizations that figure out that distinction first will define how this industry works for the next decade.